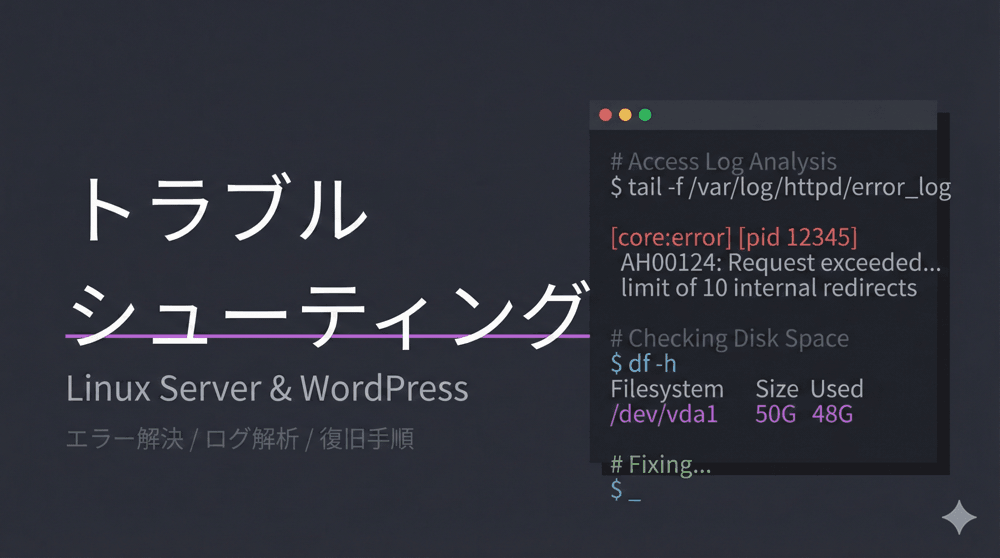
障害は、突然やってくる。
こんにちは!「LINUX工房」管理人の「リナックス先生」です。
今回は、これまでの連載講座とは少し趣向を変えて、全エンジニアが避けて通れない「障害対応」にフォーカスした特別講義をお届けします。
平穏な午後、突然Slackやメールでこんな連絡が来たら、あなたはどうしますか?
「なんかWebサイトが重いんですけど…」
「APIのレスポンスが返ってきません!」
この瞬間、エンジニアの心拍数は跳ね上がります。
先生、まさに今それです!
自作したアプリのサーバーが、急にモッサリし始めました。
慌てて再起動したら直ったんですけど、またすぐに重くなって…。
とりあえずCPUのコア数を増やそうかと思ってるんですけど、それで解決しますか?
コウ君、それは「闇雲な対症療法」よ。
風邪で熱があるのに、原因も調べずに胃薬を飲むようなもの。
サーバーが重い原因はCPUだけじゃないわ。「ディスクの読み書きが詰まっている」「メモリが足りない」「ネットワークがパンクしている」など様々よ。
今回は、プロのエンジニアが障害発生時に行っている「原因切り分けのフローチャート」を叩き込んであげるわ!
本記事では、Linuxサーバー(AlmaLinux/Ubuntu共通)におけるパフォーマンス低下の原因を特定するためのコマンド操作、数値の読み方、そして具体的な対処法を体系的に解説します。
📚 関連する過去記事
トラブルシューティングの前に、基礎環境の復習はこちら。
第1章:まずは現状把握。「top」と「Load Average」の真実
サーバーにSSHでログインできたら、最初に打つコマンドは決まっています。top です。
1. Load Average(ロードアベレージ)を見る
top コマンドを実行し、右上に表示される数値に注目してください。
top - 10:00:01 up 10 days, 1:23, 1 user, load average: 5.24, 2.10, 1.05
この 5.24, 2.10, 1.05 という3つの数字は、左から順に「直近1分、5分、15分」のシステムの負荷状況を表しています。
数字の意味:CPU使用率ではない!
ここを勘違いしている人が多いですが、Load Averageは「CPU使用率」ではありません。
正確には「CPUでの処理を待っているプロセス + ディスクI/Oの完了を待っているプロセス」の数です。
- CPUコア数が「1」の場合: Load Averageが 1.0 を超えたら混雑している。
- CPUコア数が「4」の場合: Load Averageが 4.0 までは正常範囲。
まず grep -c processor /proc/cpuinfo でCPUのコア数を確認し、それに対してLoad Averageがどれくらい高いかを確認しましょう。
コア数より遥かに高い(例:4コアなのにLoad Average 20)なら、異常事態です。
2. CPU使用率の内訳を見る (%Cpu)
次に、top 画面の %Cpu(s) の行を見ます。
%Cpu(s): 10.5 us, 2.0 sy, 0.0 ni, 85.0 id, 2.3 wa, 0.0 hi, 0.2 si
この内訳が、犯人探しの最初の手がかりです。
| 項目 | 意味 | 疑うべき原因 |
|---|---|---|
| us (user) | ユーザー空間の処理 | プログラム(PHP, Python, Javaなど)の暴走、重い計算処理。 |
| sy (system) | カーネル空間の処理 | ドライバの不具合、大量のシステムコール、コンテキストスイッチの多発。 |
| wa (iowait) | ディスクI/O待ち | HDD/SSDへの書き込み・読み込みが詰まっている。(今回の最重要ポイント) |
| id (idle) | 暇な状態 | ここが多いのにLoad Averageが高い場合、ディスクI/Oが原因の可能性大。 |
💡 プロの経験則:Load Averageが高いのにCPUが暇?
「Load Averageは10もあるのに、CPU使用率(us)は5%しかない。id(idle)が90%もある」。
初心者が最も混乱するパターンです。
この場合、犯人は十中八九「ディスクI/O(wa)」です。
CPUは仕事をしたくても、HDDからのデータ読み込みが終わらずに「待ちぼうけ」を食らっている状態です。
このケースではCPUを増設しても意味がありません。SSDへ交換するか、DBのチューニングが必要です。
第2章:CPUが原因の場合の深掘り
%Cpu の us が高い場合、特定のプロセスがCPUを独占しています。
暴走プロセスの特定
top コマンドの画面で P キー(Shift + p)を押すと、CPU使用率順にソートされます。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1234 www-data 20 0 500000 30000 5000 R 99.9 1.0 5:00.00 php-fpm
この例では、php-fpm プロセスがCPUを100%近く使い続けています。
無限ループに入っているか、非常に重い計算(画像処理や暗号化など)を行っている可能性があります。
対処法
- プロセスの詳細確認:
ps -ef | grep 1234で、具体的に何を実行しているプロセスか確認します。 - 一時的な対処:
kill 1234でプロセスを強制終了させ、サーバーを安定させます。 - 根本対策:
アプリケーションのログ(/var/log/nginx/error.logや/var/log/messages)を確認し、プログラムのバグを修正します。
第3章:ディスクI/Oが原因の場合の深掘り
wa (iowait) が高い場合、ディスクアクセスがボトルネックになっています。
これを確認するためのコマンドが iostat と iotop です。
1. iostat でディスク全体の負荷を見る
sysstat パッケージに入っています(なければ dnf install sysstat)。
iostat -x 1
1秒ごとに更新されます。一番右の %util に注目してください。
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util sda 0.00 0.00 0.00 150.00 0.00 50000.00 666.67 2.50 15.00 0.00 15.00 6.67 100.00
%util が 100% に張り付いていたら、ディスクの性能限界です。
読み込み(r/s)が多いのか、書き込み(w/s)が多いのかを確認します。
2. iotop で犯人プロセスを特定する
「どのプロセスがディスクを使っているか」を知るには iotop が便利です。
 |
[改訂第4版]Linuxコマンドポケットリファレンス (Pocket reference) 新品価格 |
sudo iotop
DISK WRITE や DISK READ が高いプロセスが犯人です。
よくある原因:
- MySQL/MariaDB: 重いクエリによる大量の読み書き。
- Backup処理: 巨大なファイルの圧縮やコピー。
- ログ出力: エラーログが秒間数千行レベルで書き込まれている。
- Swap: メモリ不足によるスワップアウト(後述)。
⚠️ トラブルシューティング:Uninterruptible Sleep (State D)
top コマンドのステータス(S)欄に 「D」 と表示されているプロセスはありませんか?
これは「ディスクI/O待ちで、割り込み不可能なスリープ状態」を意味します。
この状態のプロセスは、kill -9 でも殺せません。
I/Oが解消されるのを待つか、OSごと再起動するしかありません。
Load Averageが異常に高いのにCPUが暇な時は、この「D状態」のプロセスが大量に溜まっていることが原因です。
第4章:メモリ不足と「OOM Killer」の恐怖
「サーバーが急に反応しなくなった後、勝手に再起動した」「MySQLが突然落ちた」。
こういう怪奇現象の原因は、たいていメモリ不足です。
1. free コマンドで空き容量を見る
free -h
total used free shared buff/cache available Mem: 7.6G 7.0G 100M 50M 500M 200M Swap: 2.0G 2.0G 0B
- Swap used: ここが少しでも使われていたら危険信号。物理メモリが足りていません。
- available: 実質的にアプリが使える残りメモリです。ここが極端に少ないと危険です。
2. OOM Killer (Out Of Memory Killer)
Linuxカーネルには、メモリが完全に枯渇してシステムが停止するのを防ぐため、「メモリを食っているプロセスを強制的に殺す」という機能があります。
これがOOM Killerです。
確認方法:
dmesg | grep -i "killed process" # または grep -i "Out of memory" /var/log/messages
もしログが見つかったら、メモリ不足が確定です。
殺されたプロセス(mysqldやjavaなど)がメモリを使いすぎています。
対処法
- 設定の見直し: MySQLの
innodb_buffer_pool_sizeや、Apache/Nginxのワーカー数、PHP-FPMのpm.max_childrenを減らします。 - メモリ増設: 物理的に足りないなら、VPSのプランを上げるしかありません。
- スワップ領域の追加: 緊急避難として、スワップファイルを追加して落ちないようにします(ただし動作は激重になります)。
第5章:ネットワークと接続数の調査
CPUもメモリもディスクも余裕がある。なのに繋がらない。
それはネットワーク接続数(コネクション)の上限かもしれません。
接続数の確認 (ssコマンド)
昔は netstat でしたが、今は ss コマンドを使います。
# 状態ごとの接続数をカウント
ss -ant | awk '{print $1}' | sort | uniq -c
20 ESTAB
50 LISTEN
5000 TIME_WAIT
TIME_WAIT が異常に多い(数千〜数万)場合、ポートが枯渇して新規接続ができなくなっている可能性があります。
これは高負荷なWebサーバーやリバースプロキシ環境でよく起こります。
対処法
カーネルパラメータ(sysctl)を調整して、TIME_WAITの再利用を許可します。/etc/sysctl.conf に以下のような設定を追加することを検討します。
net.ipv4.tcp_tw_reuse = 1 net.core.somaxconn = 65535
※設定変更は慎重に行ってください。
第6章:実際のトラブル事例と解決策(ケーススタディ)
最後に、私が実際に遭遇したトラブル事例を紹介します。
「あるある」ネタとして頭の片隅に入れておいてください。
事例1:夜中の2時に毎日サーバーが重くなる
- 現象: 毎日決まった時間にアラートが鳴る。Load Averageが急上昇。
- 調査:
topを見ても特定のプロセスが見当たらない(すぐ終わっている?)。crontab -lを確認。 - 原因: バックアップスクリプトが動いていた。データベースのダンプと、数GBの画像データのtar圧縮を同時に行い、ディスクI/Oが張り付いていた。
- 解決:
niceコマンドとioniceコマンドを使って、バックアップ処理の優先度を下げた。
事例2:データベースのCPUが100%に張り付く
- 現象: Webサイトの表示が極端に遅い。DBサーバーのCPUが100%。
- 調査: MySQLで
SHOW FULL PROCESSLISTを実行。 - 原因: インデックスが貼られていないカラムに対して、数百万行のテーブルを全件検索(Full Table Scan)するクエリが走っていた。
- 解決: 該当カラムにインデックスを追加(
ALTER TABLE ... ADD INDEX)。CPU負荷は一瞬で数%まで落ちた。
事例3:海外からの大量アクセスで帯域枯渇
- 現象: サーバーのリソースは余裕があるのに、サイトが表示されない。
- 調査: Nginxのアクセスログを
tail -fで確認。 - 原因: 特定の海外IPアドレス帯から、秒間数百回のスクレイピング攻撃が来ていた。ネットワーク帯域(100Mbps)を使い切っていた。
- 解決: 第6回で紹介したNginxのIP制限と、Cloudflare(CDN)を導入してエッジでブロックした。
まとめ:推測するな、計測せよ。
トラブルシューティングで最も大切なこと。
それは「思い込みで設定を変えないこと」です。
「たぶんメモリ不足だろ」と思ってメモリを増やしても、原因がディスクI/Oなら1円も無駄になります。
必ず今回紹介したコマンド(top, iostat, vmstat, free, logs)を使って「証拠」を掴んでください。
数字は嘘をつきません。
今回のトラブルシューティング・チェックリスト:
- Load Averageは高いか?(CPUコア数と比較)
- CPU負荷の内訳は?(userならプログラム、iowaitならディスク)
- メモリは足りているか?(Swap発生、OOM Killerの痕跡)
- ディスクI/Oは限界か?(%utilが100%)
- ログにエラーが出ていないか?(/var/log/messages, nginx/error.log)
この手順をマスターすれば、あなたはもう「サーバーが重い」という言葉に怯えることはありません。
冷静にターミナルを開き、外科医のように患部を特定し、治療できるエンジニアになれるはずです。
トラブルは、エンジニアを成長させる最高の教材です。
さあ、今日も元気にログを読みましょう!
Happy Debugging!
▼ スキルアップしてトラブルに強くなる ▼
実験用サーバーで技を磨く
「VPS」で自分専用環境
障害対応スキルを武器にする
「ITエンジニア転職」

コメント