「サーバーは生きてます」という報告に、何の意味もありません。
こんにちは!「LINUX工房」管理人の「リナックス先生」です。
前回は、Keepalivedを使ってサーバーが故障しても止まらない「高可用性(HA)」構成を作りました。
これで、サーバーがダウンするという最悪の事態は防げるようになりました。
しかし、現場でエンジニアを苦しめるのは「完全なダウン」ではありません。
「なんとなく重い」「時々エラーが出る」「特定の処理だけ遅い」といった、「死んではいないが、健康的でもない状態」です。
これを検知できない限り、あなたはユーザーからのクレームで初めて障害を知ることになります。
先生、耳が痛いです…。
先日も上司に「サイトが遅いぞ」って言われて、topコマンドとかログとか必死に見たんですけど、原因がわからなくて。
「CPUは余裕あります!メモリも平気です!」って報告したら、「じゃあなんで遅いんだ!」って怒られました。
サーバーの中身をレントゲンみたいに見る方法はないんですか?
それこそが今回のテーマ、「可観測性(Observability)」よ。
単なる死活監視(Monitoring)は「生か死か」しか分からない。
可観測性は「なぜ遅いか」「どこで詰まっているか」をデータで語る技術なの。
今回は、Nginxの今の状態をグラフ化して、SF映画のコックピットみたいな監視画面を作るわよ!
本記事では、Nginxのステータスを外部に公開する設定、メトリクス収集ツール「Prometheus」、可視化ツール「Grafana」の導入、さらにはアクセスログをグラフ化する「Loki」まで、フルスタックな監視基盤の構築手順を徹底解説します。
🚀 Nginx応用講座(全8回)カリキュラム
現在地:【第6回】可観測性(Observability)の確保。Prometheus/Grafana連携とカスタムメトリクス
- 【第1回】大規模負荷分散とキャッシュ戦略。数万リクエストをさばく「Proxy Cache」と「Upstream」の極意
- 【第2回】WAF(Web Application Firewall)の構築。ModSecurityと最新のNginxセキュリティ
- 【第3回】マイクロサービス時代のルーティング。gRPC、WebSocket、認証プロキシ(auth_request)の統合
- 【第4回】Nginxをプログラマブルに。Lua言語(OpenResty)による動的処理と機能拡張
- 【第5回】絶対停止させない高可用性(HA)。KeepalivedによるVIP管理とフェイルオーバー
- 【第6回】可観測性(Observability)の確保。Prometheus/Grafana連携とカスタムメトリクス
- 【第7回】動的モジュールとカスタムビルド。必要な機能だけを組み込む軽量化テクニック
- 【第8回】Kubernetes Ingress Controller入門。クラウドネイティブ時代のNginx運用
※基本講座の復習はこちら:Nginx基本講座(全8回)アーカイブ
第1章:監視のパラダイムシフト。「死活監視」から「可観測性」へ
構築に入る前に、言葉の定義をアップデートしておきましょう。
Monitoring(監視)とは
「既知の失敗」を見つけることです。
例:「CPU使用率が90%を超えたらアラート」「Pingが通らなくなったら通知」
これらは「想定内」のトラブルには対応できますが、「想定外」の事象(例:特定の商品ページだけDBクエリが遅い)には無力です。
Observability(可観測性)とは
「未知の失敗」を調査できるようにすることです。
メトリクス(数値)、ログ(記録)、トレース(追跡)の3つのデータを詳細に収集・蓄積し、「システム内部の状態を、外部出力データから推測できる能力」を指します。
これにより、「なぜ遅いのか」をデータドリブンで突き止めることができます。
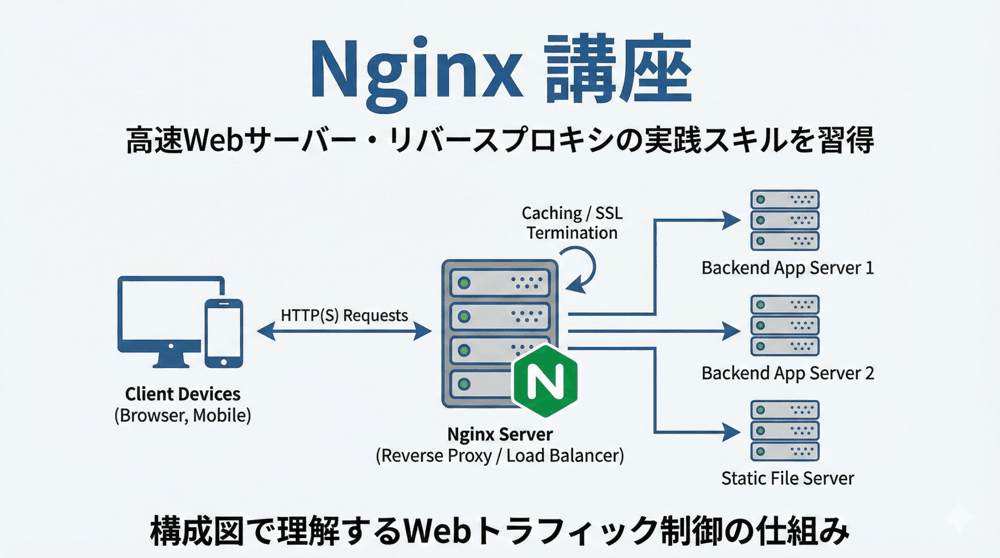
第2章:Nginxの健康診断書。「stub_status」の有効化
まずはNginx自身に、「今の自分の状態(接続数や処理数)」を喋らせる必要があります。
これを行うのが標準モジュール ngx_http_stub_status_module です。
設定手順
/etc/nginx/conf.d/status.conf などの設定ファイルを作成し、以下の location を定義します。
※セキュリティのため、ローカル(127.0.0.1)または監視サーバーからのアクセスのみ許可します。
server {
listen 8080;
server_name localhost;
location /metrics {
stub_status on;
access_log off; # 監視アクセスのログは不要
allow 127.0.0.1; # ローカルホストを許可
allow 192.168.1.0/24; # 社内LANなどを許可
deny all;
}
}
設定をリロード後、curl http://127.0.0.1:8080/metrics を叩いてみてください。
Active connections: 2 server accepts handled requests 105 105 320 Reading: 0 Writing: 1 Waiting: 1
これがNginxの生体データです。
- Active connections: 現在の同時接続数。
- accepts/handled: 受け付けた接続総数と、処理した接続総数(ここが乖離していたら設定ミスで接続を落としている)。
- requests: 処理したリクエスト総数。
しかし、これだけではただのテキストデータです。
これを時系列でグラフにするために、Prometheusを使います。
第3章:現代の監視スタック。「Prometheus」と「Exporter」の構築
ここからは、監視システムを構築します。
今回は管理が容易な Docker Compose を使って、一気に以下の3つを立ち上げます。
- Nginx Prometheus Exporter: Nginxの
stub_statusを読み取り、Prometheus形式に変換する翻訳機。 - Prometheus: メトリクスデータを定期的に収集(スクレイピング)し、時系列データベースに保存するサーバー。
- Grafana: Prometheusのデータを美しくグラフ化するダッシュボードツール。
docker-compose.yml の作成
作業ディレクトリを作成し、以下のファイルを作成します。
version: '3.8'
services:
# 1. Nginx Exporter
nginx-exporter:
image: nginx/nginx-prometheus-exporter:latest
command:
- -nginx.scrape-uri=http://host.docker.internal:8080/metrics
ports:
- "9113:9113"
extra_hosts:
- "host.docker.internal:host-gateway"
# 2. Prometheus
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
# 3. Grafana
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
prometheus.yml の作成
Prometheusがどこからデータを取ってくるかを定義する設定ファイルです。
global:
scrape_interval: 15s # 15秒ごとに収集
scrape_configs:
- job_name: 'nginx'
static_configs:
- targets: ['nginx-exporter:9113']
起動
docker-compose up -d
これで、ポート3000番でGrafanaが、9090番でPrometheusが起動しました。
たったこれだけで、現代的な監視基盤の土台が完成です。
第4章:数値をグラフに変える魔法。「Grafana」のダッシュボード構築
ブラウザで http://サーバーIP:3000 にアクセスし、Grafanaにログインします(ID/Passはどちらも admin)。
ステップ1:データソースの追加
- 左メニューの歯車アイコン → Data Sources をクリック。
- Add data source をクリックし、Prometheus を選択。
- URL欄に
http://prometheus:9090と入力(Docker内の通信なのでサービス名でOK)。 - 一番下の Save & Test をクリックして成功すれば接続完了です。
ステップ2:ダッシュボードのインポート
一からグラフを作る必要はありません。
世界中のエンジニアが作ったテンプレートを使いましょう。
 | Rocky Linux & AlmaLinux実践ガイド (impress top gear) [ 古賀 政純 ] 価格:3520円 |
- 左メニューの + アイコン → Import をクリック。
- 「Import via grafana.com」の欄に、ID 12708 または 11199 を入力して Load をクリック。
(※IDは変わる可能性があるため、Grafana公式サイトで “Nginx Prometheus Exporter” で検索するのが確実です) - データソースに先ほど追加したPrometheusを選択し、Import をクリック。
すると、目の前に美しいグラフが現れます!
「現在の秒間リクエスト数」「エラー率」「通信トラフィック」などがリアルタイムで動いているはずです。
これが可観測性です。
第5章:【上級編】ログもグラフで見たい。「Loki」によるアクセスログ解析
メトリクス(数値)だけでは、「どのURLが404になっているか」「どのIPからのアクセスが多いか」といった詳細までは分かりません。
そこで、アクセスログそのものを解析するツール Loki(ロキ) を追加します。
NginxログのJSON化
解析しやすくするために、NginxのログをJSON形式にします(基礎講座第8回参照)。
log_format json_analytics escape=json '{'
'"time": "$time_iso8601",'
'"remote_addr": "$remote_addr",'
'"status": $status,'
'"request": "$request",'
'"request_time": $request_time,'
'"user_agent": "$http_user_agent"'
'}';
access_log /var/log/nginx/access_json.log json_analytics;
PromtailとLokiの追加
docker-compose.yml に以下を追加します。
loki:
image: grafana/loki:latest
ports:
- "3100:3100"
promtail:
image: grafana/promtail:latest
volumes:
- /var/log/nginx:/var/log/nginx # ホストのログをマウント
- ./promtail-config.yml:/etc/promtail/config.yml
これでGrafanaにLokiデータソースを追加すれば、SQLのようにログを検索したり、「ステータスコードごとの割合」を円グラフにしたりできるようになります。
「エラーが増えた瞬間、どのURLへのアクセスが集中していたか」が一目瞭然になります。
💡 プロのノウハウ:LogQLを使いこなせ
Lokiの検索言語「LogQL」を使えば、以下のような強力なクエリが書けます。
{job="nginx"} |= "error" | json | status >= 500
(意味:nginxのログの中から、”error”という文字を含み、かつJSONパースした結果statusが500以上のものを抽出)
grepコマンドでログを漁る日々とはおさらばです。
第6章:現場で役立つ監視項目とアラート設定の勘所
最後に、プロが「何を見ているか」という監視のポイントをお伝えします。
1. Request Rate(リクエスト数)
急激なスパイク(DDoS攻撃やバズり)を検知します。
また、逆に「急にゼロになった」場合も、Nginxの手前(LBやFirewall)での障害を疑います。
2. Error Rate(エラー率)
「エラー数」ではなく「全リクエストに対するエラーの割合」を見ます。
アクセスが増えればエラー数が増えるのは当然ですが、エラー率が跳ね上がったら異常事態です。
5xx系エラー率が 1% を超えたらSlackに通知、といったルールを設定します。
3. Latency(レイテンシ/応答速度)
平均値だけでなく、95パーセンタイル(p95)や99パーセンタイル(p99)を見ます。
「平均は0.1秒だけど、一部のユーザーだけ10秒待たされている」という隠れた遅延を発見するためです。
4. Saturation(飽和度)
Nginxのワーカー接続数が worker_connections 上限に近づいていないか。
ファイルディスクリプタが枯渇していないか。
リソースの限界が近づいている予兆を捉えます。
まとめ:見えないものは、改善できない。
お疲れ様でした!
今回は、Nginxを中心とした最新の可観測性環境を構築しました。
今回の重要ポイント:
stub_statusはNginxのバイタルサイン。必ず有効化する。- Prometheus + Grafana は、現代の監視のデファクトスタンダード。
- ログをJSON化しLokiで解析することで、メトリクスでは分からない詳細が見える。
- エラー率やレイテンシのp99など、「ユーザー体験」に直結する指標を監視する。
これで、あなたのサーバーは「ブラックボックス」ではなくなりました。
「なんか重い」と言われたら、すぐにGrafanaを開き、「ああ、〇〇のAPIの応答が遅れてますね。DBのインデックスが効いてないっぽいです」と、データに基づいて即答できるエンジニアになりましょう。
さて、ここまでは「既存のNginx」を使ってきましたが、実はNginxは自分でコンパイルしてビルドすることで、さらに軽量化したり、特殊な機能(GoogleのPageSpeedモジュールなど)を追加したりできます。
「パッケージ版では満足できない」「極限までチューニングしたい」。
そんな職人エンジニアのために、次回はNginxのビルドの世界へ足を踏み入れます。
次回、第7回は「動的モジュールとカスタムビルド。必要な機能だけを組み込む軽量化テクニック」です。configure オプションの魔術、サードパーティモジュールの追加、そして運用中のNginxを止めることなくバイナリを差し替える「無停止アップデート」の手法まで解説します。お楽しみに!
▼ 監視基盤をハンズオンで学ぶ ▼
Prometheusを動かす
「VPS」で自分専用環境
SREエンジニアを目指す
「ITエンジニア転職」


コメント